



Conceptual blueprint to analyze experimental catalyst data
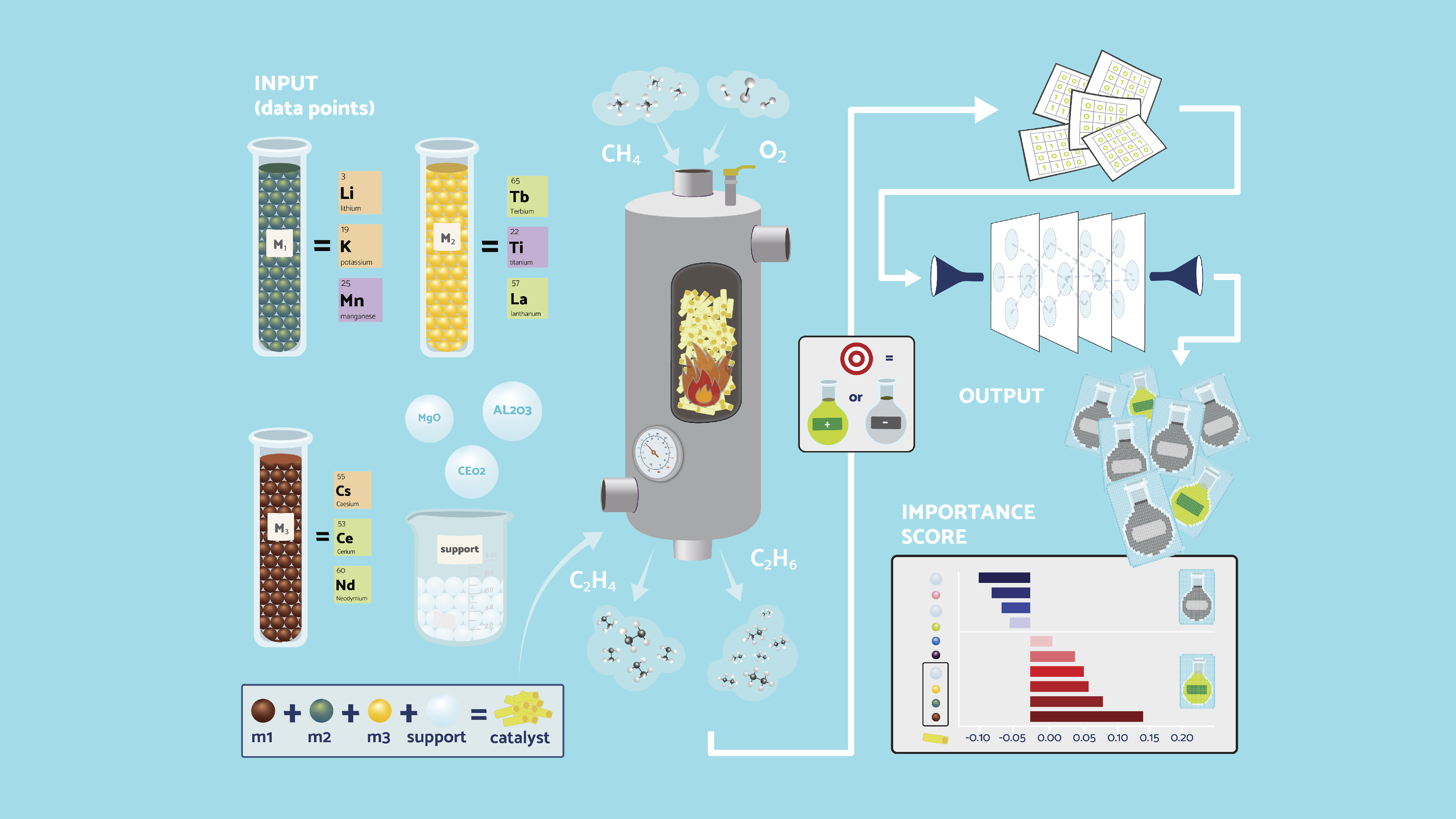
Machine learning (ML) models have recently become popular in the field of heterogeneous catalyst design. The inherent complexity of the interactions between catalyst components is very high, leading to both synergistic and antagonistic effects on catalyst yield that are difficult to disentangle. Therefore, the discovery of well-performing catalysts has long relied on serendipitous trial and error.
BIFOLD researcher Parastoo Semnani from the Machine Learning group of BIFOLD Co-Director Klaus-Robert Müller and a team of further researchers from BASLEARN, Georg-August-University Göttingen, BASF SE, Max Planck Institute for Informatics, and Korea University have now published "A Machine Learning and Explainable AI Framework Tailored for Unbalanced Experimental Catalyst Discovery" in the Journal of Physical Chemistry. In this paper they introduce a machine learning framework that deals with the challenges of experimental data and provides robust predictions of catalyst performance. Additionally they incorporate explainable AI methods in the framework that help determine which catalysis components contribute more strongly towards high-performance catalysts. The high costs associated with generating experimental catalyst data often result in small datasets biased towards low-performance catalysts. “We believe that our framework combined best practices in the field and provides a conceptual blueprint on how to work with and analyze experimental catalyst data, which should prove useful to future machine learning research efforts in this field, and help push AI-assisted Catalyst design forward” concludes Parastoo Semnani.

ACS Editors' Choice
The paper has been selected for the prestigious ACS Editors' Choice initiative. This honor is awarded to one article each day from the entire ACS portfolio of 64+ peer-reviewed journals, recognizing research with broad public interest and significant scientific impact.
The selection is based on recommendations from ACS journal editors, who are leading researchers worldwide. As part of this recognition, the paper will be made freely available for six months, maximizing its visibility and accessibility. This selection highlights the importance and potential impact of this work on the scientific community and beyond.
Abstract: The successful application of machine learning (ML) in catalyst design has been made difficult by the challenges associated with collecting high-quality and diverse data. Due to the complex interactions between catalyst components, the design of novel catalysts has long relied on trial-and-error, a costly and labor-intensive process that results in scarce data that is heavily biased toward undesired, low-yield catalysts. Such data presents a challenge for training ML models that generalize well to novel compositions, which is necessary for the success of ML-guided catalyst discovery. Despite the growing popularity of ML applications in this field, most efforts so far have not focused on dealing with the challenges presented by such experimental data. In this work, we introduce a robust ML and explainable artificial intelligence (XAI) framework that incorporates a series of well-established ML methods designed to improve model performance and provide reliable evaluations for catalytic yield classification in the context of scarce and class-imbalanced data. We apply this framework to classify the yields of different catalyst combinations in the oxidative coupling of methane reaction and use it to evaluate the performance of a range of ML models: tree-based models (such as decision trees, random forest, and gradient boosted trees), logistic regression, support vector machines, and neural networks. Our experiments demonstrate that the methods used in our framework lead to more robust performance estimates and reduce the effect of class imbalance on model training, resulting in significant improvements in the predictive capability of all but one of the evaluated models. Additionally, the XAI component of the framework analyzes the decision-making process of each ML model by identifying the most important features for predicting catalyst performance. Our analysis found that XAI methods that provide class-aware explanations, such as Layer-wise Relevance Propagation, managed to identify key components that contribute specifically to high-yield catalysts. These findings align with chemical intuition and existing literature, reinforcing their validity. We believe this framework can serve as a blueprint and a set of best practices for ML applications in catalysis, driving future research while delivering robust models and actionable insights that can assist chemists in designing and discovering novel catalysts with superior performance.
Publication: A Machine Learning and Explainable AI Framework Tailored for Unbalanced Experimental Catalyst Discovery; Parastoo Semnani, Mihail Bogojeski, Florian Bley, Zizheng Zhang, Qiong Wu, Thomas Kneib, Jan Herrmann, Christoph Weisser, Florina Patcas, and Klaus-Robert Müller
The Journal of Physical Chemistry C Article ASAP
DOI: 10.1021/acs.jpcc.4c05332