




How overlooked flawed prediction strategies propagate through commonly used machine learning models
Foundation models such as GPT, Llama, CLIP, etc. or other generative AI techniques are all trained by unsupervised learning methods, for example self-supervision. These foundation models have become the basis for numerous developments of specialized AI models for the sciences or industry, for example in medical diagnosis. This raises the fundamental concern of how accurately and transparently foundation models make their decisions. The problem: If the foundation model bases its correct decisions – for example – on data quality artefacts then this so-called Clever Hans effect can severely compromise the foundation model. Moreover, this effect can propagate through all specialized models that are being built using the compromised foundation model as a basis, potentially leading to unexpected malfunction in real-world applications. A team of BIFOLD scientists has analyzed several commonly used foundation models in the field of image recognition and for the first time has shown that these unsupervised learning models indeed suffer from Clever Hans (CH) effects. Specifically, they found that unsupervised learning models often produce compromised representations from which instances can be correctly predicted, although only supported by data artefacts. The flawed prediction strategy is not detectable by common evaluation benchmarks but can now be detected through their work, which has been published in the prestigious journal Nature Machine Intelligence.
The Clever Hans effect in machine learning describes a situation where an AI model makes correct predictions but relies on irrelevant or unexpected patterns for its decision—similar to the famous horse Clever Hans, which could not actually do arithmetic but successfully picked up on subtle cues from its owner. An example of the Clever Hans effect would be an image classification model designed to recognize horses, but instead of identifying the actual animal, it bases its decision primarily on the presence of an unnoticed watermark (e.g., "horse images").
Explainable AI uncovers Clever-Hans-Effects
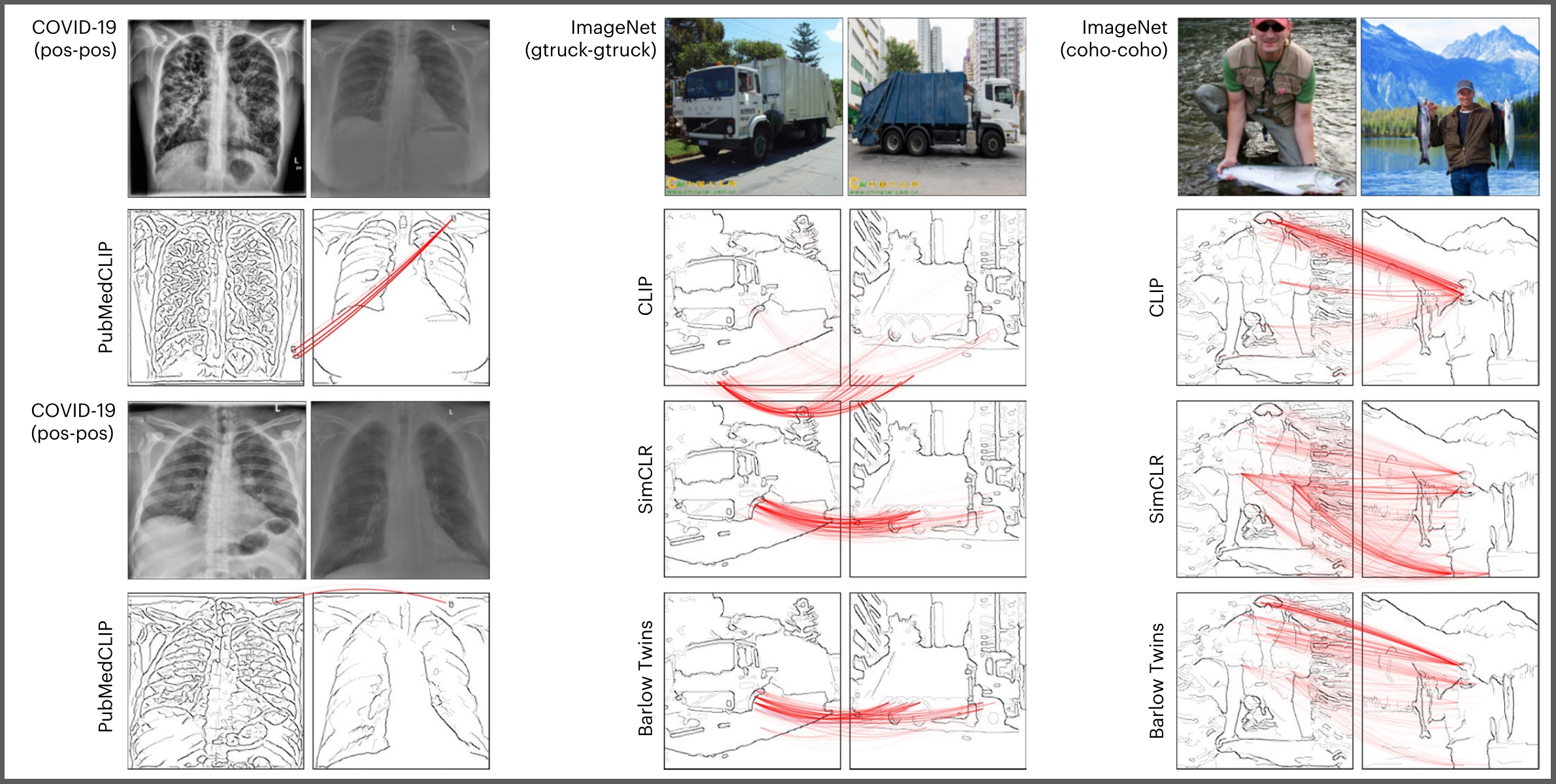
For their new publication, the researchers demonstrated the existence of Clever Hans effects, for example, in the context of medical data: PubMedCLIP, a foundation model of medical images, typically succeeds at representing two similar lung X-rays as similar, but largely based on spurious textual annotations they have in common rather than looking at the pixels in the lung regions. This can lead to significant robustness issues in downstream diagnostic tasks. The spurious strategy of looking at text, however, is inherited from the CLIP model, a prominent unsupervised foundation model for image data that PubMedCLIP specializes upon. CLIP and other unsupervised foundation models being the starting point for many new downstream applications, they effectively become a single point of failure. “It is essential to re-examine the unsupervised learning paradigm on which these models are based to ensure that the produced models are reliable and do not contaminate their downstream supervised models with CH effects," explains BIFOLD researcher Prof. Dr. Grégoire Montavon. The BIFOLD researchers uncovered CLIP's uncanny artifact reading strategy using higher-order Explainable AI techniques based on LRP (Layer wise Relevance Propagation). "Particularly useful for this purpose is an Explainable AI method called BiLRP, which not only highlights which pixels the unsupervised model is looking at, but also how these pixels interact to make two images appear similar or dissimilar," explains Grégoire Montavon. The researchers found, for example, that the CLIP model over emphazises specific features such as text or faces. The researchers also demonstrated that Explainable AI can be used to detect these hidden flaws and, in some cases, remove them from the base foundation model.
Unsupervised learning predates foundation models, and has been applied to virtually any data set for which there are no labels. Classical unsupervised problems include organizing data into clusters, or finding anomalous instances in a dataset, a common starting point for quality control in real world problems of industrial manufacturing. The BIFOLD researchers present a further relevant example of a Clever Hans strategy in these models, where the anomaly scores of popular models are largely supported by task-irrelevant high frequency features. Interestingly, they found that not only can an increase in in data noise cause an anomaly model to malfunction, but a decrease in data noise can also fool the model into thinking that every instance is normal and failing to raise an alarm in the presence of truly anomalous instances. While Clever Hans effects have been extensively studied in supervised learning, there has been a lack of similar studies in the context of unsupervised learning. “The Clever Hans effect in unsupervised learning, coupled with the fact that unsupervised learning is the essence of foundation model training and therefore powers many downstream applications, is a cause for concern. Explainable AI and our recent developments are an effective way to detect and address this in the quest for reliable and trustworthy AI systems.” concludes BIFOLD Co-director Klaus-Robert Müller.
Publication:
https://www.nature.com/articles/s42256-025-01000-2